Return to home page
Project #2
Measuring the statistical significance of an ad campaign (A/B testing)
File Repository
Raw Data (.csv)
Python Script (.py)
Python Script (.txt)
Utility of A/B testing
A/B testing is a statistical evaluation of two pre-determined design choices randomly assigned to a pool of users, usually in the context of front-end development and marketing analysis.
The objective of these tests is simply to verify which design choice, if any, leads to improvement in a desired metric, such as click rates, retention or purchases/subscriptions.
It is also possible to analyse more than two design choices (colours of a subscription button) or a chain of independent design choices (colour → size → font of a subscription button),
though this would be referred to as multivariate analysis.
This project aimed to develop my automation skills in the context of an A/B analysis on the significance of a realistic ad campaign (ie. marketing analysis). I have set up several functions which will
correctly pick out the most appropriate test (more on this later) based on the results of several assumption checks - in order to determine the significance of the ad campaign if the data receives an update.
Vigorous A/B testing is especially crucial in the context of marketing analysis over classic user interface examples, as rolling out an ad campaign involves significantly higher costs (e.g. planning,
asset design, potential contracts) than updating a website, therefore making the correct* data-driven decision is particularly vital in order to maximise firm revenue and minimise unnecessary losses.
(* with posterior beliefs based on available data)
Data description & visualisation
With 588,101 observations of unique individuals, this dataset is designed to capture changes in consumer purchasing patterns (converted variable, i.e. did the individual buy or disregard the product)
at various levels of ad exposure.
The categorisation of a control group (individuals who have not seen any ads) and the experimental group (individuals exposed to the ads at least once) creates the foundation of the A/B significance analysis.
Further variables enable us to explore the nuances of customer behaviour:
- The total number of times the ads were exposed to the individual
- The day of the week when the individual was exposed to the greatest number of ads
- The hour at which the individual was exposed to the greatest number of ads
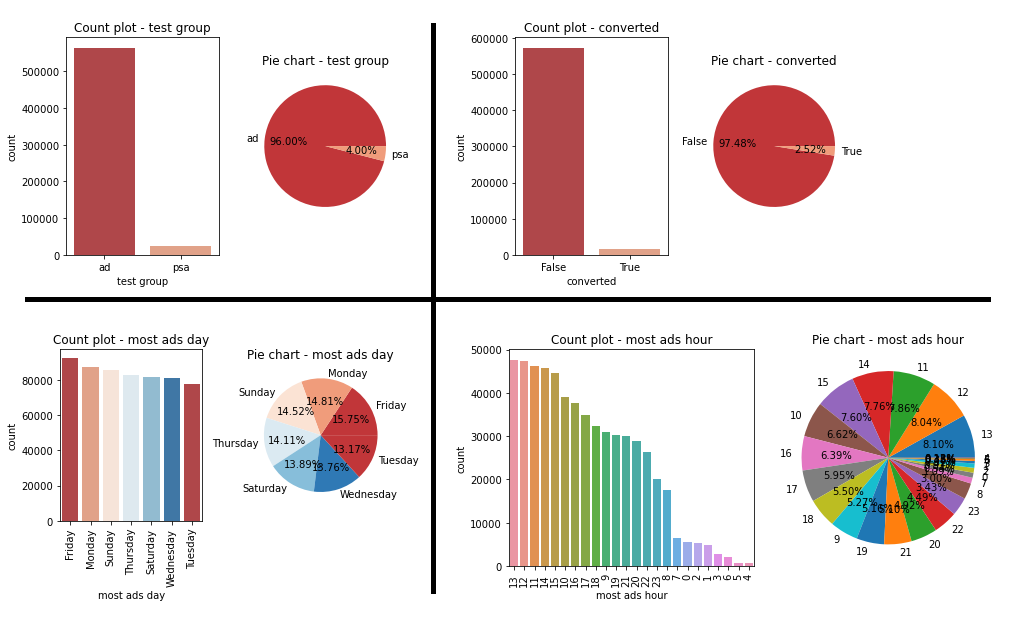
Elementary univariate visualisation of:
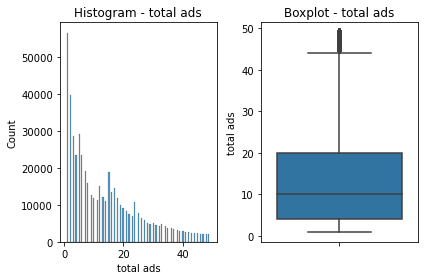
categoric variables & non-categoric 'total ads' variable
(filtered out extreme outliers for spread clarity in latter).
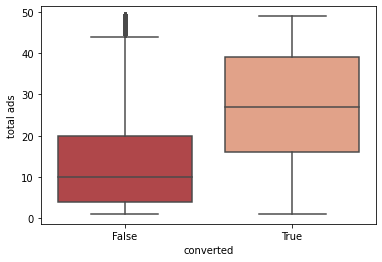
Bivariate visualisation of the distribution of the number of ads seen by those have purchased the product and those who haven't
(filtered extreme values for spread clarity).
Based on the boxplot above, if we find the ad campaign to make significant changes to sales rates, individuals should be targeted to face ad exposure about 26 times.
Mondays (3.3%), Tuesdays (3.0%) and Wednesdays (2.5%) were the days with the highest proportion of successful transactions, and the late afternoon and evening hours of the day (15:00 - 20:00) received the
greatest proportion of successful traffic ranging from 2.6% to 3.1% of converted customers.
{kind=link}
{kind=link}
{kind=link}
A/B Testing between the two groups
Test 1: Chi-Square Test
It's important to isolate each variable against the customer conversions, and by running the Chi-Square test, we can outrule the likelihood of the association being determined by random chance.
Having conducted the test for each variable at a 1% significance level, a statistically significant relationship between the variables and conversion rates was found in all cases.
Test 2: A/B Test Function Nest
With a sample size as large as this data is, it's a no-brainer to run non-parametric tests in the real world, as it omits testing for the conditions necessary for parametric tests
(which assume normal distribution & equal variance). However, my goal for this analysis is to be able to use this code no matter what variation of the data gets funneled into it
(for instance, a particular subset of the same variables), therefore I have created a chain of functions using various tests from the SciPy package to automatically select the most appropriate
statistical tests regardless.
The first function tests for the assumptions required for parametric tests: the Shapiro-Wilkinson test for normal distribution (5% alpha), and Levene's test for measuring the equality of variances.
Based on the result of these tests, the second function picks either the optimal parametric test to determine the statistical impact of the ad campaign, the t-test (compares data through the mean),
or its optimal non-parametric alternative, the Mann-Whitney U test (compares data through the median).
In this case, both assumption tests defied the null hypothesis (p < 0.05), meaning the data is not normally distributed and that there is heteroskedasticity in my data (variance across groups are not equal).
Therefore, it's only appropriate to run the non-parametric Mann-Whitney U test to determine the significance of the results of the ad campaign. With a p-value of 0.0, there is extremely strong
statistical evidence to say there is a difference between the results of the control and treatment group, implying that the ad campaign does indeed successfully increase the proportion of people who will
buy the product.
Conclusion
This project demonstrates the application of automation in A/B testing to evaluate the significance of a realistic ad campaign, with a focus on identifying statistically supported insights
that drive decision-making in marketing. By using a dataset of 588,101 unique observations, I explored consumer behaviour patterns, highlighted key trends, and successfully automated the selection of
optimal statistical tests to ensure robustness.
Key findings revealed a significant relationship between ad exposure and conversion rates. Late afternoons and early evenings were particularly effective for driving successful transactions,
and individuals exposed to ads approximately 26 times showed the most promising results.
Non-parametric testing via the Mann-Whitney U test confirmed the ad campaign's positive impact on purchase rates, providing sufficient evidence to guide marketing strategy.
{Back to Top}